If your website features a username+password authentication system, you owe it to your users to offer 2-factor authentication (or 2fa for short) as an additional measure of protection for their accounts. If you're unfamiliar with 2fa, it's that step in the login sequence that asks the user for a (typically) 6-digit numeric code in order to complete user authentication. The 6 digit codes are either sent to the user's phone as a text message upon a login attempt or generated by an app such as Google Authenticator. Codes have a short validity period of typically 30 or 60 seconds. This tutorial will show you how to implement such a system using java in a way that is compatible with Google Authenticator. Other compatible 2FA apps should work too although I haven't tested any others against the code in this tutorial.
Your first idea for implementing the server side component of a 2fa system might be to randomly generate 6 digit codes with short validity periods and send them to the user's phone in response to a login attempt. One major shortcoming with this approach is that your implementation wouldn't be compatible with 2fa apps such as Google Authenticator which many users will prefer to use. In order to build a 2fa system that is compatible with Google Authenticator, we need to know what algorithm it uses to generate codes. Fortunately, there is an RCF which precisely specifies the algorithm. RFC 6238 describes the "time-based one-time password" algorithm, or TOTP for short. The TOTP algorithm combines a one time password (or secret key) and the current time to generate codes that change as time marches forward. RFC 6238 also includes a reference implementation in java under the commercial-friendly Simplified BSD license. This tutorial will show you how to use code from the RFC to build a working 2fa system that could easily be adapted into your java project. Let's get started.
Go https://tools.ietf.org/html/rfc6238 Appendix A and cut/paste the java code that is the reference implementation into a file called TOTP.java. Don't forget to remove the page breaks so you'll have valid java code you can compile. Note: The reference implementation isn't contained in a package, which means it cannot easily be imported from other java packages. I recommend creating a package called org.ietf.tools (from the RFC domain name as per java package naming convention) and moving the TOTP class into it.
The TOTP reference implementation takes its inputs in hex and Google Authenticator takes input in base32. So we'll need to do a little back and forth conversion to get these 2 tools speaking the same language. For that, we'll use Apache Commons Codec. If you're using maven, add the following to your pom.xml:
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.10</version>
</dependency>
The groupId, artifactId and version should work with your non-maven dependency management tool of choice too, e.g. gradle, ivy, etc.
The first thing we'll need to do is generate a secret key. Google Authenticator expects 20 bytes encoded as a base32 string. We'll want to use a cryptographically secure pseudo-random number generator to generate our 20 bytes, then encode it to base32. Some users will opt to key in their secret key manually instead of scanning a QR code (which we will also generate shortly). So, as a final touch we'll prettify the key by lower-casing it and adding whitespace (which Google Authenticator ignores) after each group of 4 characters. Here's the code to do it:
public static String getRandomSecretKey() {
SecureRandom random = new SecureRandom();
byte[] bytes = new byte[20];
random.nextBytes(bytes);
Base32 base32 = new Base32();
String secretKey = base32.encodeToString(bytes);
// make the secret key more human-readable by lower-casing and
// inserting spaces between each group of 4 characters
return secretKey.toLowerCase().replaceAll("(.{4})(?=.{4})", "$1 ");
}
A secret key generated by the above method is enough to create a test entry within Google Authenticator. Call this method once to generate a secret key and save it somewhere. We'll use it a few more times in this tutorial. Here is the secret key I generated, which I'll be using for the remaining examples in this tutorial:
quu6 ea2g horg md22 sn2y ku6v kisc kyag
Go ahead and open up the Google Authenticator app (free in the App Store) on your mobile device and press the little plus sign near the top right to add a new entry.

Select manual entry. (Don't worry, we'll add support for the more convenient "Scan barcode" option too shortly).
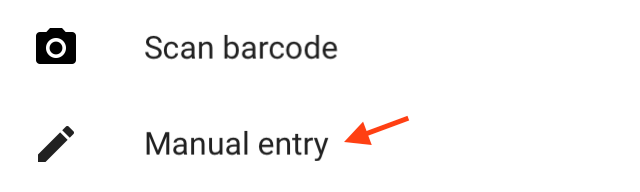
In the account field, put in a test email address, and enter your generated secret key under "Key". Leave the "Time based" toggle in the default on position. Click the checkmark in the top right to complete the addition of your new entry.
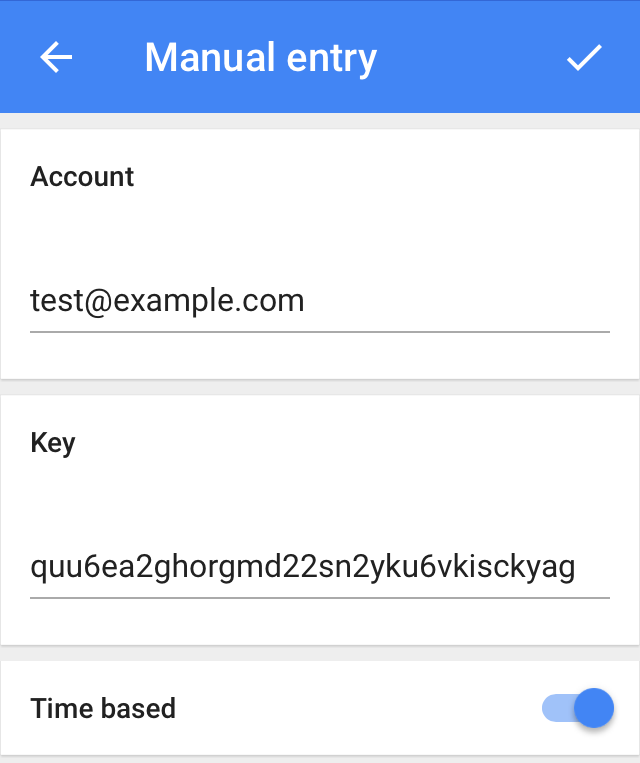
You should now see your test entry appear in the Google Authenticator UI with a 6 digit code changing every 30 seconds.

Now let's write a method that converts base32 encoded secret keys to hex and uses the TOTP class we borrowed from RFC 6238 to turn them into 6 digit codes based on the current time.
public static String getTOTPCode(String secretKey) {
String normalizedBase32Key = secretKey.replace(" ", "").toUpperCase();
Base32 base32 = new Base32();
byte[] bytes = base32.decode(normalizedBase32Key);
String hexKey = Hex.encodeHexString(bytes);
long time = (System.currentTimeMillis() / 1000) / 30;
String hexTime = Long.toHexString(time);
return TOTP.generateTOTP(hexKey, hexTime, "6");
}
We can use this method in a simple loop to generate time-based 6 digit codes in sync with Google Authenticator. Here's how the code looks:
String secretKey = "quu6 ea2g horg md22 sn2y ku6v kisc kyag";
String lastCode = null;
while (true) {
String code = getTOTPCode(secretKey);
if (!code.equals(lastCode)) {
// output a new 6 digit code
System.out.println(code);
}
lastCode = code;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {};
}
If you've wired things up correctly, you should should be able to run the above loop and see the same 6 digit codes being printed by Google Authenticator and your java code in unison. And you should experience that warm & fuzzy "Cool, it's actually working" feeling that programmers get when things go right. If the example isn't working, double check that you've used the same secret key in your test code as you manually entered into Google Authenticator and that you didn't miskey it when you typed it into your phone. Also, validate that the clocks are correct and in sync on your computer and phone. After all, these 6 digit codes are time-based.
As mentioned above, the most convenient way for users to import a secret key into Google Authenticator is to scan a QR code. And generating this QR code is pretty straight-forward. The first thing we'll need is a library that generates QR codes. Let's use Google's ZXing library. Here is the dependency you'll need:
<dependency>
<groupId>com.google.zxing</groupId>
<artifactId>javase</artifactId>
<version>3.2.1</version>
</dependency>
The next part of this of the puzzle is constructing a string to encode into the QR code such that Google Authenticator can read it. Fortunately Google provides good documentation on the key uri format. For all the gory detail, feel free to dive into the docs, but in a nutshell, this is the format (replace tokens surrounded by curly braces with their corresponding dynamic values):
otpauth://totp/{issuer}:{account}?secret={secret}&issuer={issuer}
Some things to note about this string:
- Account is the user-facing id on your system, typically a username or email address. It's used to label entries within Google Authenticator.
- Issuer is a company or organization name and is also used for labelling purposes.
- Issuer appears twice. It's not a typo. The docs recommend putting this value in 2 places.
- All dynamic values must be URL encoded.
- The colon can be a literal colon or may be url encoded as %3A.
- Google Authenticator doesn't seem to deal with spaces encoded as plus signs gracefully. Encoding spaces as %20 seems to work.
Putting all that together, here's a short method that will generate the string we'll use as input when generating our QR code:
public static String getGoogleAuthenticatorBarCode(String secretKey, String account, String issuer) {
String normalizedBase32Key = secretKey.replace(" ", "").toUpperCase();
try {
return "otpauth://totp/"
+ URLEncoder.encode(issuer + ":" + account, "UTF-8").replace("+", "%20")
+ "?secret=" + URLEncoder.encode(normalizedBase32Key, "UTF-8").replace("+", "%20")
+ "&issuer=" + URLEncoder.encode(issuer, "UTF-8").replace("+", "%20");
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
Call this method with your previously generated secret key, a test email address for account, and "Test Company" as the value for issuer. Save the result for the next step. It should look similar to this (with no line breaks):
otpauth://totp/Example%20Company%3Atest%40example.com?secret=QUU6EA2GHORGMD22SN2YKU6VKISCKYAG&issuer=Example%20Company
Now let's use ZXing to generate a QR code for us in PNG format:
public static void createQRCode(String barCodeData, String filePath, int height, int width)
throws WriterException, IOException {
BitMatrix matrix = new MultiFormatWriter().encode(barCodeData, BarcodeFormat.QR_CODE,
width, height);
try (FileOutputStream out = new FileOutputStream(filePath)) {
MatrixToImageWriter.writeToStream(matrix, "png", out);
}
}
Calling this method with the string returned by the method in the previous step as the 1st argument will write a PNG image to the specified path. (Note: if your server doesn't have a graphics card, you'll need to make sure java is running with the java.awt.headless=true option.) Here is an example QR code image I generated using the same secret key from the manual entry example above:

Go ahead and try to use your generated image with the "Scan barcode" option you saw previously in Google Authenticator. If all is well and right in the programming universe, you should now have a new entry within your Google Authenticator app that was created from the PNG image you generated and produces the same 6 digit values at the same time as your manually keyed in entry and your java code. Notice this time the issuer appears at the top; a nice touch that we get with the barcode scan, that we don't get with manual key entry.
If it works, congrats! It's time to do a victory lap. If not, please double check your code against the demo code for this tutorial on GitHub. If you're still having an issue after that, please leave me a comment as I'm sure it's all my fault and I'll do my best to help you get your example code working.
Now that you've got the nuts and bolts of 2fa and Google Authenticator integration working, it's up to you to integrate these snippets into your own website or app. I'll leave the mundane MVC details to you. Don't forget that some of your users will inevitably lose their phones and be locked out of their accounts. So you should provide your users with the ability to generate about 10 one-time use backup codes that can be used for logging in case of an emergency. You can use a method similar to getRandomSecretKey() above to generate cryptographically secure one-time use backup codes. In order to defend against brute force attacks, be sure to apply rate-limiting on any endpoints you expose that process 2fa requests. Also, it's a good idea to invalidate tokens once they are used to prevent replay attacks. And finally, this should go without saying, but always use a secure https connection!
Another rather neat application of the code snippets presented here is in integration testing. You can use the getTOTPCode() method above in a Selenium test for your site's 2fa login system or even social logins with Google, GitHub or any other site supporting TOTP-based 2fa. All you need is the manual entry version of the secret key string.
I've released all code in this tutorial on GitHub under the same commercial-friendly Simplified BSD license used by the reference implementation within the RFC. So now there is nothing stopping you. Go forth and make your users more secure!


