Update: This post made the front page of Hacker News! Check out the discussion on
HN.
Those of you who are avid readers of my Stack Overflow profile know that I am the creator of JGuitar.com, a popular guitar chord and scale calculator website. I'm also a longtime fan of Apple products. So you can imagine my surprise and delight when I received this message in my inbox this week from a JGuitar user:
Is there a way to select a specific instrument (like ukulele) via the URL - so that I'd have a link that would take me right to chord search for that instrument?
I am starting to mess around with iOS's new shortcut function. They have a shortcut for searching chords on your website, but it defaults to guitar; I'd like to make a ukulele version of the shortcut.
Hold on a sec... Did Apple really integrate their new iOS shortcuts feature with my website? How is it possible I didn't know this was coming? No one from Apple reached out to me. I had eagerly upgraded my iPhone X to iOS 12 earlier that day but hadn't yet discovered "shortcuts". Naturally, I immediately wanted to see this in action.
After a little googling, I learned that in order to add shortcuts, you need to download the Shortcuts App from the Apple App Store.
After installing and launching the Shortcuts app, you're greeted to an empty Library screen. In order to use a shortcut, you need to either create one from scratch or select a pre-made shortcut from the gallery. I clicked on the Gallery icon, scrolled down to the "Tools for Making Music" section and saw the "Guitar Chord Finder" shortcut.
Could this be it? The description didn't mention JGuitar.com. I clicked on it. There were instructions for how to use the shortcut but still no mention of JGuitar.com. When I clicked "show actions" it revealed the "actions" that make up the shortcut and I could finally see the JGuitar.com link in the URL section. Here are the complete actions that make up the Guitar Chord Finder Shortcut.
In a nutshell, the shortcut uses the user's input (a chord symbol) to construct a url to a chord search result page on JGuitar.com and then looks for 200x200px chord diagram images on that page and shows them to the user. The rest of the web page isn't shown.
There are a couple of things I would have done differently in these shortcut actions. Firstly, I would have used an https url instead of http and secondly, I would have made it look for images with a width & height greater than 200px rather than equal to 200px. That would give me the flexibility to boost image resolution without breaking the shortcut. And boosting image resolution is an easy change for me since all the chord diagram images are dynamically generated on the fly and cached.
Now that I had found and understood the feature it was time to take it for a test drive. I added the Guitar Chord Finder Shortcut to my Library and played with it both within the Shortcuts App and via the voice command: "Hey Siri: Guitar Chord Finder". Both worked as expected.
I was also able to easily modify the shortcut to support ukulele as requested by my user. I just added ?instrument=Ukulele to the url field and replaced the image width rule with one that matches images with width greater than 100px.
To check if users are actually using this feature, I scanned my log files. Sure enough, the following user agent string started appearing thousands of times a day in jguitar.com's web server logs on 9/17/2018:
Shortcuts/700 CFNetwork/974.2.1 Darwin/18.0.0
I'm genuinely thrilled that someone at Apple deemed my chord calculator technology worthy of inclusion in the iOS shortcuts gallery. If anyone from Apple is reading this, please reach out using JGuitar.com's contact form. We can work together to make this experience even better. I can provide high quality SVG images of all chord diagrams, support alternate tunings, instruments and more.
If your website features a username+password authentication system, you owe it to your users to offer 2-factor authentication (or 2fa for short) as an additional measure of protection for their accounts. If you're unfamiliar with 2fa, it's that step in the login sequence that asks the user for a (typically) 6-digit numeric code in order to complete user authentication. The 6 digit codes are either sent to the user's phone as a text message upon a login attempt or generated by an app such as Google Authenticator. Codes have a short validity period of typically 30 or 60 seconds. This tutorial will show you how to implement such a system using java in a way that is compatible with Google Authenticator. Other compatible 2FA apps should work too although I haven't tested any others against the code in this tutorial.
Your first idea for implementing the server side component of a 2fa system might be to randomly generate 6 digit codes with short validity periods and send them to the user's phone in response to a login attempt. One major shortcoming with this approach is that your implementation wouldn't be compatible with 2fa apps such as Google Authenticator which many users will prefer to use. In order to build a 2fa system that is compatible with Google Authenticator, we need to know what algorithm it uses to generate codes. Fortunately, there is an RCF which precisely specifies the algorithm. RFC 6238 describes the "time-based one-time password" algorithm, or TOTP for short. The TOTP algorithm combines a one time password (or secret key) and the current time to generate codes that change as time marches forward. RFC 6238 also includes a reference implementation in java under the commercial-friendly Simplified BSD license. This tutorial will show you how to use code from the RFC to build a working 2fa system that could easily be adapted into your java project. Let's get started.
Go https://tools.ietf.org/html/rfc6238 Appendix A and cut/paste the java code that is the reference implementation into a file called TOTP.java. Don't forget to remove the page breaks so you'll have valid java code you can compile. Note: The reference implementation isn't contained in a package, which means it cannot easily be imported from other java packages. I recommend creating a package called org.ietf.tools (from the RFC domain name as per java package naming convention) and moving the TOTP class into it.
The TOTP reference implementation takes its inputs in hex and Google Authenticator takes input in base32. So we'll need to do a little back and forth conversion to get these 2 tools speaking the same language. For that, we'll use Apache Commons Codec. If you're using maven, add the following to your pom.xml:
The groupId, artifactId and version should work with your non-maven dependency management tool of choice too, e.g. gradle, ivy, etc.
The first thing we'll need to do is generate a secret key. Google Authenticator expects 20 bytes encoded as a base32 string. We'll want to use a cryptographically secure pseudo-random number generator to generate our 20 bytes, then encode it to base32. Some users will opt to key in their secret key manually instead of scanning a QR code (which we will also generate shortly). So, as a final touch we'll prettify the key by lower-casing it and adding whitespace (which Google Authenticator ignores) after each group of 4 characters. Here's the code to do it:
public static String getRandomSecretKey() {
SecureRandom random = new SecureRandom();
byte[] bytes = new byte[20];
random.nextBytes(bytes);
Base32 base32 = new Base32();
String secretKey = base32.encodeToString(bytes);
// make the secret key more human-readable by lower-casing and
// inserting spaces between each group of 4 characters
return secretKey.toLowerCase().replaceAll("(.{4})(?=.{4})", "$1 ");
}
A secret key generated by the above method is enough to create a test entry within Google Authenticator. Call this method once to generate a secret key and save it somewhere. We'll use it a few more times in this tutorial. Here is the secret key I generated, which I'll be using for the remaining examples in this tutorial:
quu6 ea2g horg md22 sn2y ku6v kisc kyag
Go ahead and open up the Google Authenticator app (free in the App Store) on your mobile device and press the little plus sign near the top right to add a new entry.
Select manual entry. (Don't worry, we'll add support for the more convenient "Scan barcode" option too shortly).
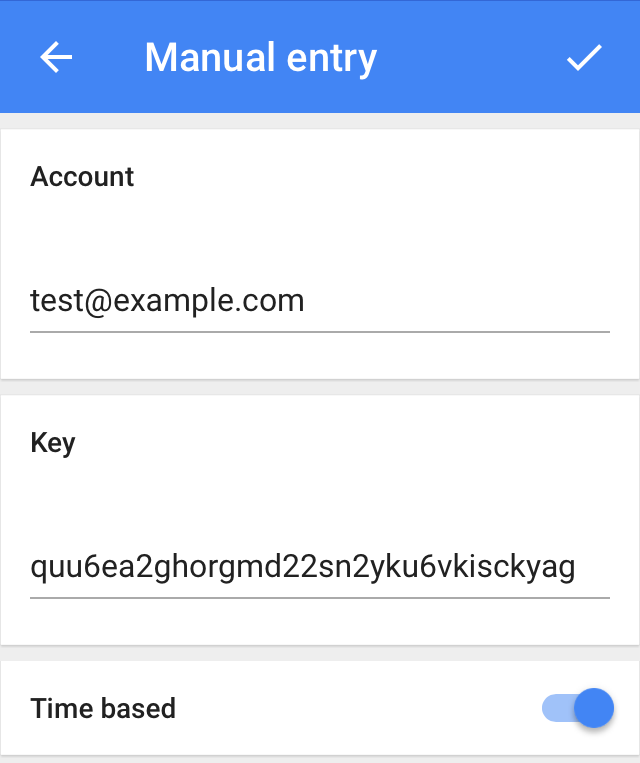
In the account field, put in a test email address, and enter your generated secret key under "Key". Leave the "Time based" toggle in the default on position. Click the checkmark in the top right to complete the addition of your new entry.
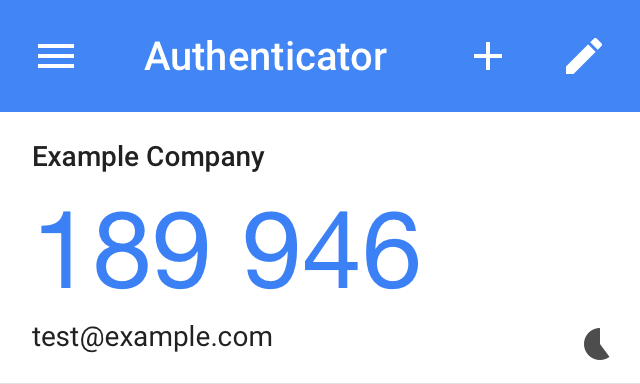
You should now see your test entry appear in the Google Authenticator UI with a 6 digit code changing every 30 seconds.
Now let's write a method that converts base32 encoded secret keys to hex and uses the TOTP class we borrowed from RFC 6238 to turn them into 6 digit codes based on the current time.
If you've wired things up correctly, you should should be able to run the above loop and see the same 6 digit codes being printed by Google Authenticator and your java code in unison. And you should experience that warm & fuzzy "Cool, it's actually working" feeling that programmers get when things go right. If the example isn't working, double check that you've used the same secret key in your test code as you manually entered into Google Authenticator and that you didn't miskey it when you typed it into your phone. Also, validate that the clocks are correct and in sync on your computer and phone. After all, these 6 digit codes are time-based.
As mentioned above, the most convenient way for users to import a secret key into Google Authenticator is to scan a QR code. And generating this QR code is pretty straight-forward. The first thing we'll need is a library that generates QR codes. Let's use Google's ZXing library. Here is the dependency you'll need:
The next part of this of the puzzle is constructing a string to encode into the QR code such that Google Authenticator can read it. Fortunately Google provides good documentation on the key uri format. For all the gory detail, feel free to dive into the docs, but in a nutshell, this is the format (replace tokens surrounded by curly braces with their corresponding dynamic values):
Call this method with your previously generated secret key, a test email address for account, and "Test Company" as the value for issuer. Save the result for the next step. It should look similar to this (with no line breaks):
Now let's use ZXing to generate a QR code for us in PNG format:
public static void createQRCode(String barCodeData, String filePath, int height, int width)
throws WriterException, IOException {
BitMatrix matrix = new MultiFormatWriter().encode(barCodeData, BarcodeFormat.QR_CODE,
width, height);
try (FileOutputStream out = new FileOutputStream(filePath)) {
MatrixToImageWriter.writeToStream(matrix, "png", out);
}
}
Calling this method with the string returned by the method in the previous step as the 1st argument will write a PNG image to the specified path. (Note: if your server doesn't have a graphics card, you'll need to make sure java is running with the java.awt.headless=true option.) Here is an example QR code image I generated using the same secret key from the manual entry example above:
Go ahead and try to use your generated image with the "Scan barcode" option you saw previously in Google Authenticator. If all is well and right in the programming universe, you should now have a new entry within your Google Authenticator app that was created from the PNG image you generated and produces the same 6 digit values at the same time as your manually keyed in entry and your java code. Notice this time the issuer appears at the top; a nice touch that we get with the barcode scan, that we don't get with manual key entry.
If it works, congrats! It's time to do a victory lap. If not, please double check your code against the demo code for this tutorial on GitHub. If you're still having an issue after that, please leave me a comment as I'm sure it's all my fault and I'll do my best to help you get your example code working.
Now that you've got the nuts and bolts of 2fa and Google Authenticator integration working, it's up to you to integrate these snippets into your own website or app. I'll leave the mundane MVC details to you. Don't forget that some of your users will inevitably lose their phones and be locked out of their accounts. So you should provide your users with the ability to generate about 10 one-time use backup codes that can be used for logging in case of an emergency. You can use a method similar to getRandomSecretKey() above to generate cryptographically secure one-time use backup codes. In order to defend against brute force attacks, be sure to apply rate-limiting on any endpoints you expose that process 2fa requests. Also, it's a good idea to invalidate tokens once they are used to prevent replay attacks. And finally, this should go without saying, but always use a secure https connection!
Another rather neat application of the code snippets presented here is in integration testing. You can use the getTOTPCode() method above in a Selenium test for your site's 2fa login system or even social logins with Google, GitHub or any other site supporting TOTP-based 2fa. All you need is the manual entry version of the secret key string.
I've released all code in this tutorial on GitHub under the same commercial-friendly Simplified BSD license used by the reference implementation within the RFC. So now there is nothing stopping you. Go forth and make your users more secure!
After a protracted quiet period, I'm rebooting my blog. Applause all around (from the 2 people who stuck around all these years waiting for a new post). As for the reasons I failed at blogging the first time around and what I can do to succeed this time, that will be the subject of a future post.
As a first step in the reboot, I decided to migrate my blog off a self-hosted Pebble/Tomcat setup and onto a free hosted blogging platform where I won't have to spend time and effort on maintenance and software/security updates. This will hopefully free me up to just focus on blogging. After an admittedly shallow search, I decided to give Blogger a try this time around. After going through the migration, I thought I would share what I like and dislike about Blogger so far. This list primarily focusses on my migration experience, configuration and first impressions. Given this is my first post on the Blogger platform, I haven't actually used the blogging features much yet. Here goes.
Things I like about Blogger:
It's free to use with a custom domain registered through Google Domains. Using my own domain name was non-negotiable for me. The fact that I could easily do that for free with Blogger + Google Domains (where all my domains are already registered) made it a win over other hosted blogging platforms.
Blogger integration with Google Domains is nice. DNS configuration for my blog was simply a checkbox in the Google Domains admin which created something Google Domains calls a synthetic record. The rest of the the configuration was within Blogger itself.
I can configure redirects. Some of the legacy Pebble urls needed to be changed to be compatible with Blogger. Broken links would have been a deal-breaker for me. Blogger allows you to specify whether the redirects are temporary or permanent. Also, query string parameters are maintained through Blogger redirects, which is a plus.
I can make "pages". ie. static web pages that aren't blog entries per se. e.g. About me. Pages are not dated and are not included in the RSS feed, etc.
The pre-fab templates look pretty good, are mobile-friendly out of the box and there were multiple template choices that suited my minimalist preferences.
Adding Google Analytics tracking was as simple as pasting my GA ID into a text box in the settings area of the Blogger admin.
Things I dislike about Blogger:
You can't use a naked domain. When I tried, I got this error message:
I had to change the canonical domain for my blog from the naked domain to www, which wasn't a deal breaker for me although I would have preferred to stick with the cleaner looking naked domain for the canonical url of my blog. At least Blogger provides a checkbox to redirect the naked domain to your chosen subdomain, www in my case. The most likely reason for not supporting naked domains is that a large scale platform such as Blogger probably has all custom domains resolve to CNAME records pointed to load balancers. These CNAMES resolve to the most optimal load balancer for the requested location. The DNS protocol doesn't support specifying CNAME records at the zone apex. Therefore, naked domains can only use an A record which can only point to an IP address. (and optionally an AAAA record pointing to an IPv6 address). Some DNS providers support CNAME-like functionality for naked domains. This is achieved by the DNS service dynamically resolving the CNAME on the fly and responding with an IP address as though it were an A record, thereby making the whole thing transparent to the client. Amazon calls these Aliases and Cloudflare calls it CNAME flattening. Still others call it an ANAME. But Google Domains doesn't seem to have this feature under any name at the moment.
You can't support https with a custom domain.
Again, this was not a deal breaker for me as my legacy blog wasn't being served over https anyway. But given the recent trend towards end to end encryption on the web, and efforts to provide free SSL certificates such as LetsEncrypt, it would be nice for Blogger to offer a solution, free or otherwise. If I do want to get this blog on https, I might have to migrate off Blogger. (Proxying through Cloudflare might be an option).
Importing my content was a pain. Fortunately, there wasn't much of it. I had only ever published one blog post which received a grand total of 4 comments. Blogger does have blog import/export support for posts and comments, but the only supported format is Blogger's own XML format. Pebble didn't seem to have an exporter for this Blogger XML format so I ended up cut/pasting my blog post, the 4 comments, and the pages I had created into Blogger's web interface. I then used the Blogger export tool to export the XML so I could spoof the authors and dates of the comments directly in the raw XML and re-import it back into Blogger. It took me several rounds to get all the timestamps/timezones right. I ended up hitting a rate limit on the import function, which forced me to wait 24 hours before attempting another import. The URL paths and slugs that Blogger allows for posts didn't line up 1:1 with my legacy blog stack's paths so I had to set up redirects in order to not break any URLs. I also had to backdate the date portion of the path to match the actual date I published the original on the legacy blog stack. This manual tinkering obviously wouldn't have scaled beyond a small number of posts and comments.
The auto-generated sitemap.xml includes blog posts but not "pages". I wanted to add them manually but I can't see any way to edit or override the auto-generated sitemap.xml. I guess the pages I created won't be in my sitemap :( Also, sitemap.xml is being served with Content-Type of application/atom+xml which I'm not sure is valid, although Google's own webmaster's tools considered the sitemap to be valid.
The custom redirects are limited to internal urls. Some of the redirects I wanted to set up were to outside sites such GitHub repos I have created but I wasn't able to make them work. There may be a sound reason this is restricted, but it was still a let-down given my non-sinister use case.
Though it's imperfect, overall Blogger feels like an upgrade from my self-hosted Pebble stack. So I'm pleased. And now it's time to stop messing with the blogging software stack and start actually blogging!
Of all the "Hello Worlds" I've cranked out as a programmer, this is perhaps the only one where the title has really been apt. Yes, I finally drank the delicious blogger kool-aid and decided to take a leap into blogdom. I guess this means I'll start using words like blogosphere, blogophilic and blogophobic. If I'm really successful, I'll even coin a new term in this blog. Here, let me try... ...It has to be a term that gets zero results when I google it. Ok, got one:
ablogual
An individual who neither blogs nor reads blogs. Not a member of the blogosphere due to either ignorance, lack of interest, a superiority/inferiority complex, or blogophobia. Sample usage: "That dude is totally ablogual. He's never even heard of Joel Spolsky."
Blogging, the sane approach vs. the Asaph approach
The sane approach to starting a new blog is to use one of the many finebloggingsoftwarepackages freely available on the web so one can focus on writing insightful, witty drivel without getting bogged down in re-inventing the wheel. Being a programmer, I was of course tempted to embark on the largely pointless task of building yet another blogging engine. I actually started down this yak shave thinking it would be only minimally distracting.
Blogging software, just a bunch of static HTML pages, right?
Like many programming tasks, writing blogging software is deceptively simple at first glance. Being new to blogging, I thought: "How hard could it be?" The truly lazy would just roll a static HTML page for each blog entry. Right? Being slightly less lazy, I made my blogging software in Java and database driven (Are you impressed?). I got the basics for that up and running relatively quickly. After a few evenings of programming I even had a functional back-end admin console. Then it occured to me that user comments would be essential. The people must be heard! But I would have to prevent comment spam somehow. Being selectively pragmatic, I decided I'd be willing to deal with that manually in the near term. One yak shave lead to another and before I knew it, I was spending time writing a Gravatar URL generator and an HTML source code syntax highlighter.
But those were just the features I could think of. The real kickers were the features I didn't know I needed because I was a blogging noob. Turns out, there is a secret XML undercurrent that moves information around the blogosphere. I don't want to miss that ride. Every blog needs an RSS feed (maybe ATOM too), pings (but not spings), pingbacks, trackbacks, linkbacks, refbacks and smackbacks. Ok, some of those are redundant and at least one is made up. But the point is I underestimated the task. That's actually not surprising at all since as a programmer, I routinely do that. If I ever give you an estimate, go ahead and double it.
After about a month, I came to my senses and decided that I should at least bootstrap my blog with an existing free solution while I roll my own. Honestly, the project is shelved indefinitely. I haven't admitted defeat but I've become keenly aware that it's probably a waste of my precious time.
Why re-invent the wheel when open source wheel libraries already exist?
The obvious choice to start is Wordpress. It's mature, solid, scalable, supported by a thriving community, has a bazillion plugins, and it appears to be the leading open source blogging solution. It's written in PHP, which while not my first choice, is a language I'm very comfortable with. I test drove it on my laptop. The install was a breeze. I simply unpacked the archive, created a MySQL database for it, set some easy config parameters and fired it up. Hitting the site in a browser for the first time prompted me to create the database schema and with that the install was pretty much complete. It worked well right away and I was ready to install it on my production server. Only one thing stood in the way. My server runs Tomcat on port 80 and Wordpress runs on Apache. There is no shortage of instructions online for proxying requests from Apache to Tomcat but almost nothing for doing the reverse. The standard advice used to be to run Apache on port 80 for static content and proxy requests for dynamic content to Tomcat running on port 8080. But since Tomcat now serves content at speeds that compete with Apache, I don't think the setup makes sense for my servers. So I set up Apache on port 8080 and set off on the task of getting Tomcat to proxy requests to Wordpress. After writing a simple proxy servlet, I discovered that Wordpress breaks this scheme by detecting that the page was served from a non-canonical URL and issues a redirect. I started digging into the Wordpress internals only to find a total mess of thousand line long non-object-oriented PHP scripts. I tried tweaking the siteurl and home entries in the options table of Wordpress's MySQL database but I couldn't get them quite right. Going with an open source solution was supposed to save time, so it was at this point that I decided to stop short of tweaking Wordpress's ugly PHP code.
The obvious next step was to look for the Java community's answer to Wordpress. This search lead me to Apache Roller. The install was very similar to Wordpress; Set up a MySQL database, deploy the code, edit a configuration file, and proceed the rest of the way with a browser based install. I didn't like having to stick an Apache Roller properties file in Tomcat's lib folder. I think an application's configuration should be in the app's lib folder, not the webserver's lib folder. but after coming this far, I was willing to live with this annoyance. The other thing I noticed about Roller on my laptop is that it seemed sluggish. The web based install actually took over a minute to complete. I tried to just put it out of my mind. After all, Apache Roller is supposedly robust and scalable enough to run Sun Microsystems' blogs. So I went ahead and installed Roller on my 2 production servers which happen to be a couple CentOS virtual machines with a paltry 256 megs of ram each. One of the servers handles all my live web traffic and the other serves as a database server and failover web server. I immediately noticed the load on the primary web server server higher than before. I hadn't even posted a blog entry yet. A couple of days later, I started seeing OutOfMemory Exceptions in Tomcat's logs and getting error reports from users for one of my high traffic sites hosted on the same VM. I hadn't had this problem before installing Roller so I immediately pulled the plug and uninstalled Roller. The memory issues seemed to be immediately and permanently resolved. I imagine that Roller, which appears to include every Jakarta subproject under the sun in its lib folder, needs a lot more horsepower than my dinky CentOS VM or my MacBook Pro could provide. If anyone has anymore insight, please leave a comment.
So with that, the search for a lightweight java based alternative to Apache Roller and Wordpress began. This lead me to Pebble, an open source java blog server supporting all the basic features I was looking for. After the Wordpress/Roller excercise, I was expecting an uphill battle. Unlike the other 2 blogging engines I tried, Pebble doesn't use a MySQL database for its backend. Instead it's based on Lucene which theoretically should make the search function of my blog perform better than Wordpress or Roller which would presumably have to rely on MySQL's rather weak full text search capabilities. I did end up tweaking my Pebble instance a little bit. While customizing robots.txt, I discovered it was being served with a Content-Type: text/html instead of text/plain. It looks like the bug is due to the fact that .txt files are set to be parsed as jsp files and are getting the default jsp Content-Type. I worked around this by adding <jsp:directive.page contentType="text/plain" /> to the top of robots.txt and it solved the problem. I should probably submit a patch for that fix. So I held my breath and installed Pebble on my production servers. Unlike with Roller, they seemed to be unaffected, which is of course a good thing. Finally, I was ready to start blogging! Maybe... Hopefully... Meh. I'm sure something will go wrong...
So I've started a blog. Now what?
So what can you expect from yet another programmer's blog?
code
tips & tricks
marginally witty commentary about programming
humerous stories about code gone bad
programming related rants
book reviews
web site reviews
warnings about quirks and strange behavior that I encounter in various APIs or software packages
shameless self promotion
fawning over my favorite technologies
bragging about projects I'm working on
miscellaneous
Traditionally, Hello World! is supposed to be just a few lines. It should certainly all fit above the fold. But economy of expression is overrated and verbosity is a programmer's friend. This has been a little long but not a bad start. Ok, now that Hello World is finished, it's time to get some real work done.